Dataset organization
Our LanEvil dataset contains two subsets, i.e., a training set with normal images and a test set with environmental illusions. We provide both training set and test set of LanEvil to download. We also provide the ground truth annotated like TuSimple. We organize the file format of the dataset as follows:
<LANEVIL BASEDIR>
├─RoadDamage
│ └─GuardRail
│ │ ├─<scene1>
│ │ │ ├─000000.png
│ │ │ ├─000001.png
│ │ │ ├─ ...
│ │ │ ├─labels.json
│ │ │ ├─labels_test.json
│ │ │ ├─labels_train.json
│ │ │ └─labels_val.json
│ │ ├─<scene2>
│ │ │ └─ ...
│ │ └─ ...
│ └─RoadCrack
│ │ └─ ...
│ └─ ...
├─TrafficObstruction
│ └─ ...
├─Shadow
│ └─ ...
└─Reflection
└─ ...
LanEvil training set

Due to the fact that not all cases that appear in the real world have environmental illusions, we use the training set consisting of 40,000 randomly sampled images to help model training.
LanEvil test set

The test part consists of 50,292 images. For each basic environmental illusion, we provide an original case without any illusion and 2 - 10 perturbed cases, each consisting of 50 to 300 consecutively captured driving images.
| The number of original and perturbed cases. | The case distribution of four illusion categories. |
|---|---|
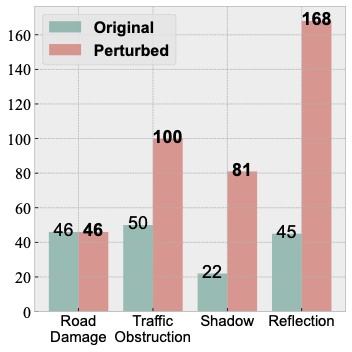
|
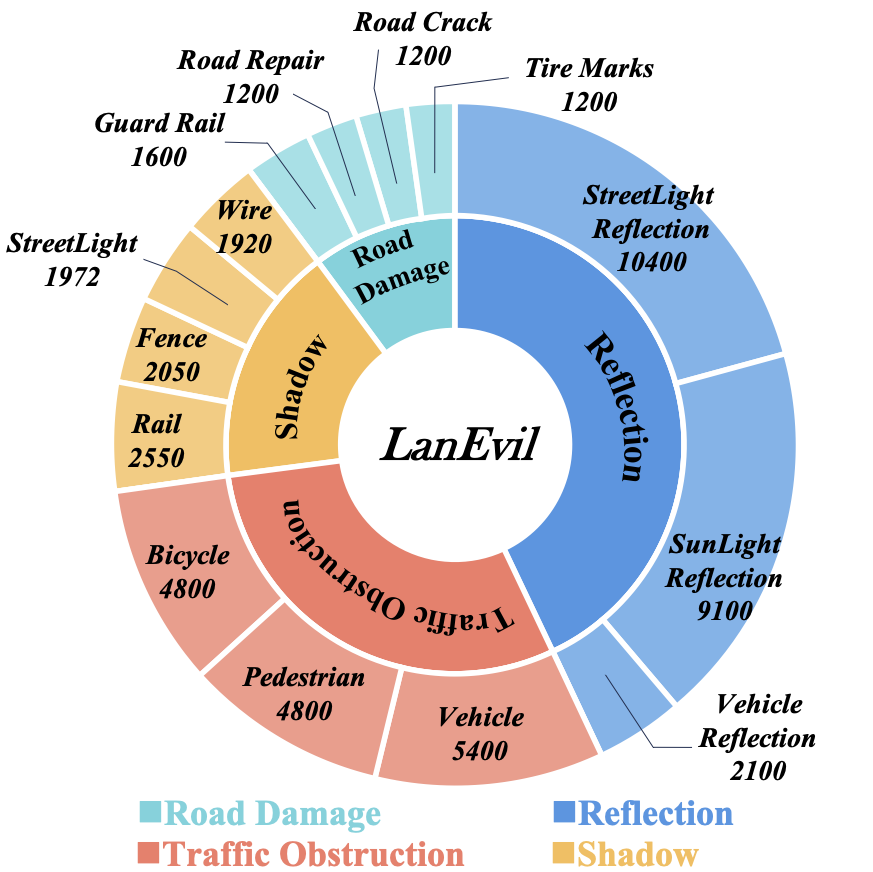
|